Când am cumpărat Mac mini-ul M2 Pro, am avut în minte un singur scop principal: editarea foto și video. Am ales varianta cu 16 GB de memorie RAM, mergând pe ideea că, dacă nu se va descurca, îi voi face retur și voi comanda o configurație superioară, de 24 GB sau poate chiar 32 GB.

S-a comportat impecabil pentru sarcinile respective, așa că l-am păstrat. Acum, însă, aproape că regret decizia. Motivul? Zilele acestea am început să mă joc serios cu noile modele lingvistice (LLM) locale, o activitate care, sincer să fiu, nu intra deloc în calculele mele la momentul achiziției.
Este surprinzător cât de rapid poate rula un model lingvistic suficient de isteț încât să-mi fie cu adevărat util pentru sarcini punctuale, însă cu o condiție majoră: să nu folosesc Mac-ul la absolut nimic altceva în acel moment. Memoria devine un blocaj evident. Cu doar 8 GB în plus, probabil n-aș mai fi avut problema asta, iar cu încă 16 GB, nici măcar grija gestionării resurselor. Așa, însă, acum mă stresează SWAP-ul care fluctuează îngrijorător; nu e ca și cum aș putea să comand alt NVMe de pe Amazon în caz că cel actual cedează.
O spun cât se poate de serios: dacă acum aș fi avut un Mac mini cu 32 GB de memorie, n-aș mai fi apelat la niciun serviciu AI premium. Pentru ce am eu nevoie, luându-mă după rezultatele testelor pe care le-am făcut, orice model generic de 12B (B = miliarde de parametri) mi-ar fi acoperit necesarul, dar imposibil de încărcat cu un context lenght decent pe configurația actuală fără a avea nevoie SWAP dacă mai folosesc și alte aplicații.
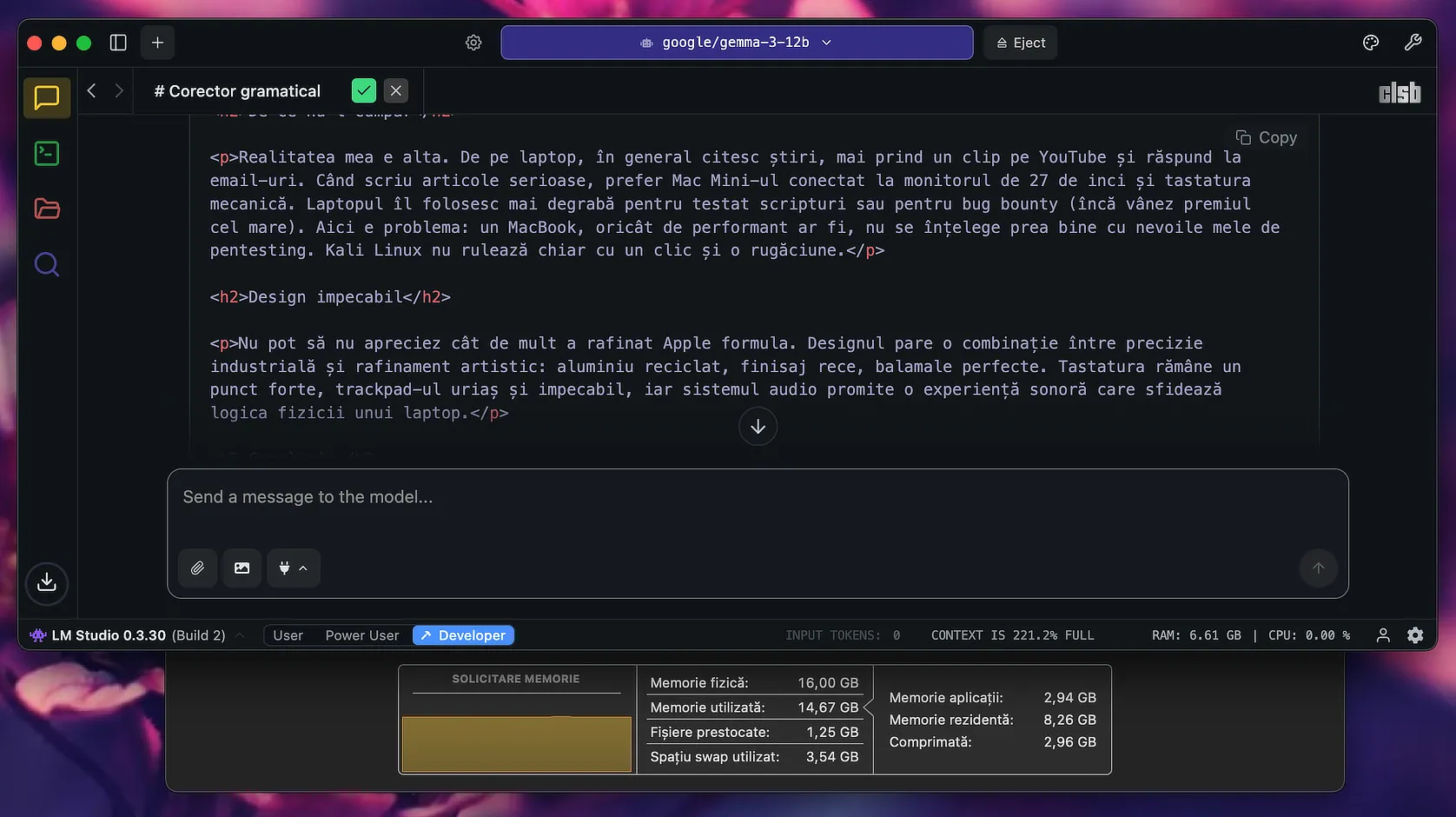
Pentru operații de corectare gramaticală, de adăugare a diacriticelor și altele asemenea, acestea s-ar descurca binișor, lucru pe care nu-l pot spune despre modelele de 7B — singurele care n-ar forța SWAP-ul — și pe care le-am testat în tot felul de scenarii (mutând intenționat focusul de pe un subiect pe altul, introducând greșeli flagrante precum „butonuri” sau „succesuri” etc.), acestea eșuând lamentabil în identificarea și corectarea lor.
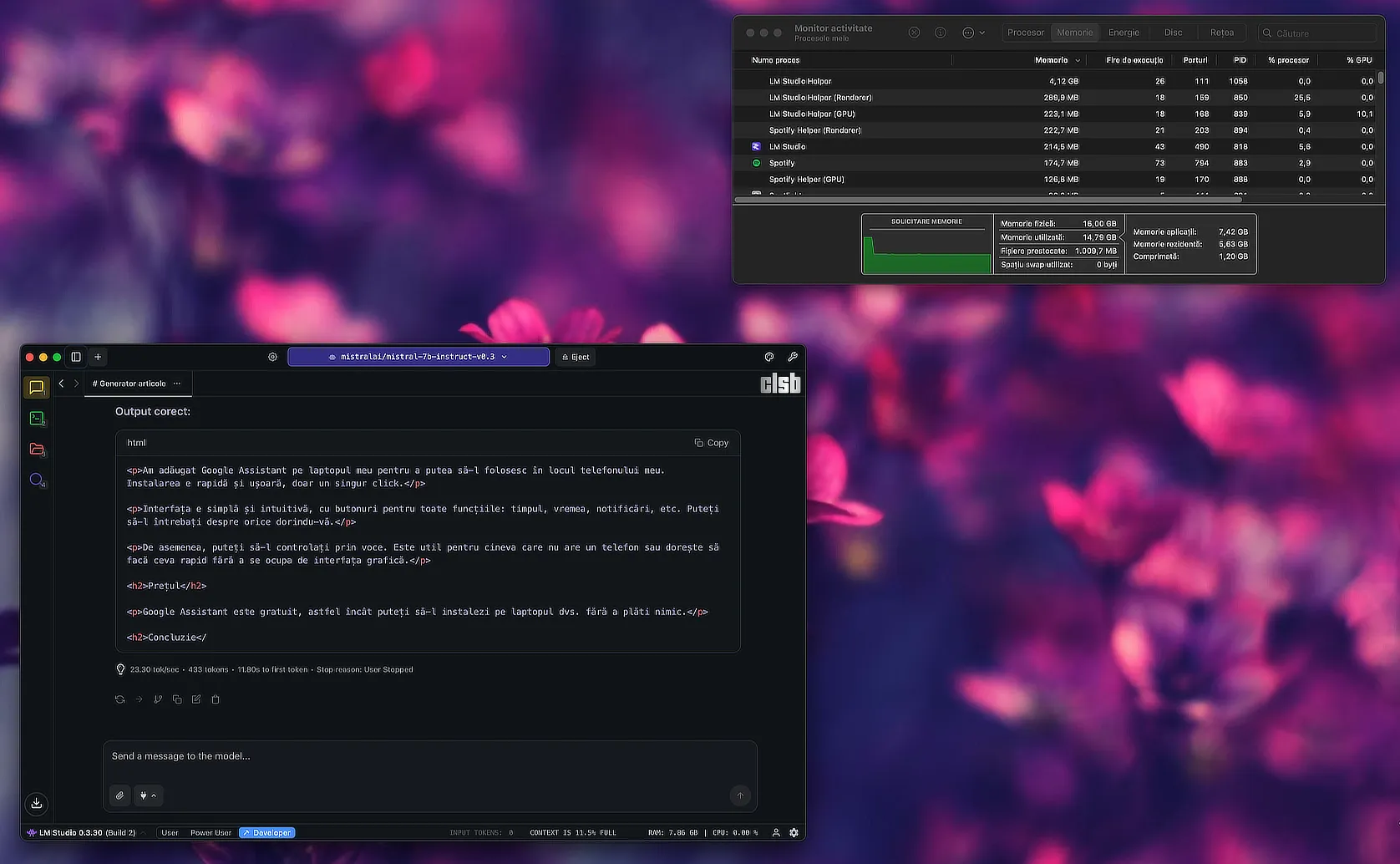
Încercați, de exemplu, să rulați un LLM pe un PC cu o placă grafică dedicată Nvidia de 8 GB VRAM, pentru a structura un curs dintr-un PDF de 400-500 de pagini. Rezultatul e decent, ba chiar promițător dacă nu ești genul nerăbdător. Modelul răspunde corect, dar lent, suficient cât să ai timp să mai verifici o notificare sau două până își termină treaba. Pe Mac, însă, aceeași sarcină se execută semnificativ mai repede și cu o coerență vizibil mai bună în răspunsuri. Aici își face simțită prezența Metal – tehnologia grafică integrată în Apple Silicon – care reușește să comunice direct cu procesorul și cu memoria unificată, fără să se împotmolească în straturi software intermediare.
Din curiozitate, am încercat același test și pe un sistem cu grafică integrată și 64 GB RAM, unde m-aș fi așteptat ca NPU-ul să dea măcar o mână de ajutor. În realitate, însă, răspunsurile veneau greu și, de cele mai multe ori, cu o logică… alternativă, ca să fiu elegant. Pe scurt, același model care pe Mac înțelegea întrebarea și revenea cu o explicație pertinentă, pe Dell părea că a luat-o pe o tangentă proprie, ca un student care a citit doar titlul cursului și improvizează.
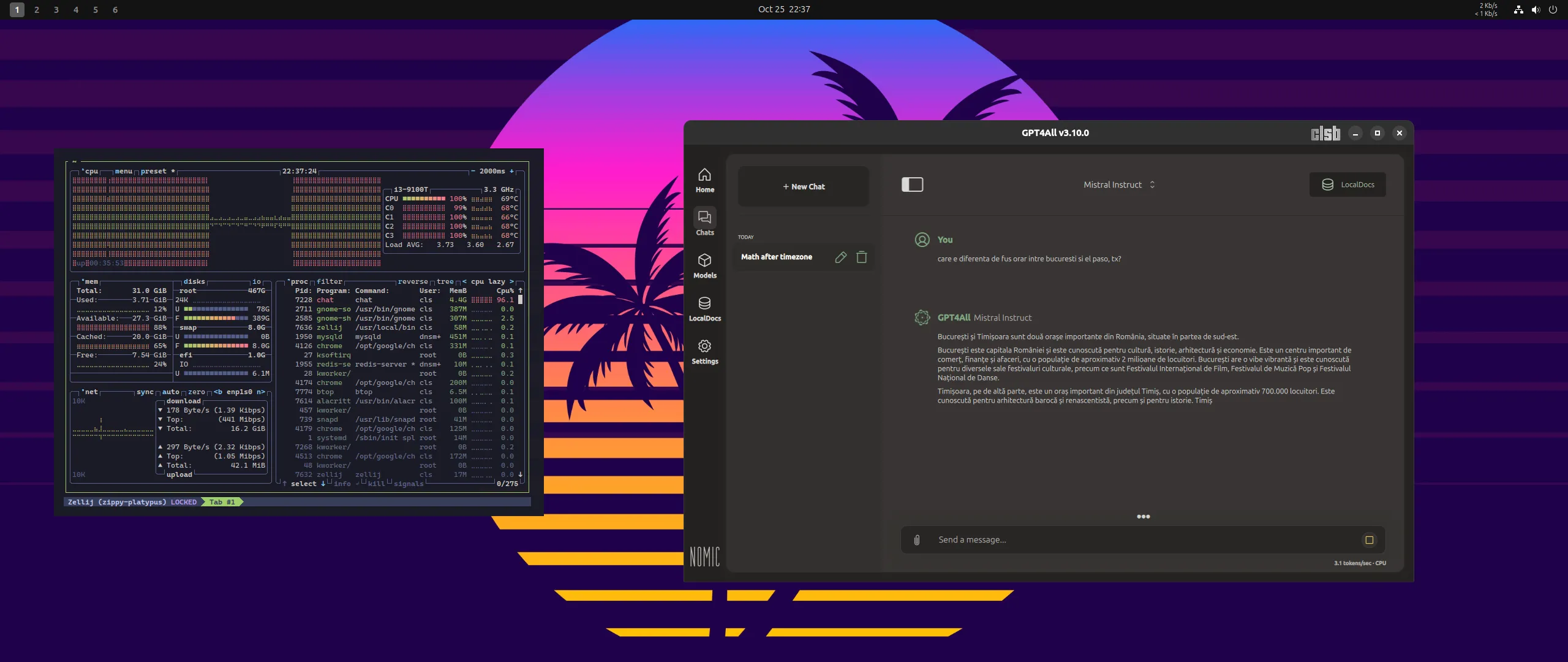
Singurul avantaj era că, dispunând de suficientă memorie RAM, putea încărca modele mai mari.
După un weekend în care am încercat toate combinațiile și configurațiile care mi-au trecut prin cap cu hardware-ul de care dispun deja, concluzia e una singură: voi plăti din nou pentru AI. Încă nu m-am hotărât pe care să-l aleg, dar , cum am mai spus, sunt mari șanse să revin la Claude.
Ceea ce simt referitor la alegerea făcută nu e neapărat un regret, ci mai mult o frustrare. Este frustrarea că aș fi avut posibilitatea de a testa mai multe LLM-uri și, eventual, chiar să antrenez câteva local – mai ales după ce am văzut experiențe surprinzătoare ale altor utilizatori cu modele de 270M (M = milioane de parametri). Bine, nu e ca și cum ar trebui să-mi vând un rinichi pentru asta, având în vedere că pot oricând apela la servicii de cloud computing cum este Google Colab, dar ca idee.
Pe de altă parte, am cumpărat exact ce îmi trebuia la momentul respectiv. Dar, dacă ar fi să-mi cumpăr un Mac acum, cu siguranță aș alege varianta cu 32 GB de RAM, fără să clipesc. Și ca să-mi fie și mai ciudă, recent am văzut la El Corte Ingles, un lanț de mall-uri renumit aici, în Spania, că același mac Mini cu M2 Pr și 32 GB de memorie costă acum cu 300 de euro mai mult decât m-a costat pe mine cel de 16 GB (ce-i drept, anul trecut altul era prețul, cam cât costă acum noul mini cu M4 Pro și 48 GB de memorie).
Poate părea mult, dar gândiți-vă cât costă plăcile video capabile să ruleze LLM-uri în condiții decente, cum ar fi o Tesla V100 sau o 5090 ROG Astral de 32 GB (mergând pe logica celor 16 GB rezervați sistemului de operare și aplicațiilor, plus 32 GB dedicați modelului). Dacă pentru mine s-ar justifica sau nu o astfel de investiție, e deja altă mâncare de pește.