Optimizarea unui server SQL nu este un proces pe care-l faci o singură dată, ci mai degrabă o rutină de mentenanță și ajustare fină. De curând, am avut ocazia să configurez de la zero un server pentru un client nou-nouț, proaspăt scos din țiplă, iar pașii pe care i-am urmat au devenit manual intern și temelia acestui ghid practic. Contextul este important: vorbim de un server cu 48 GB de RAM, dar toate calculele au fost făcute pentru 40 GB, pentru simplificarea calculelor și asigurarea unei marje generoase de resurse sistemului de operare și altor aplicații.
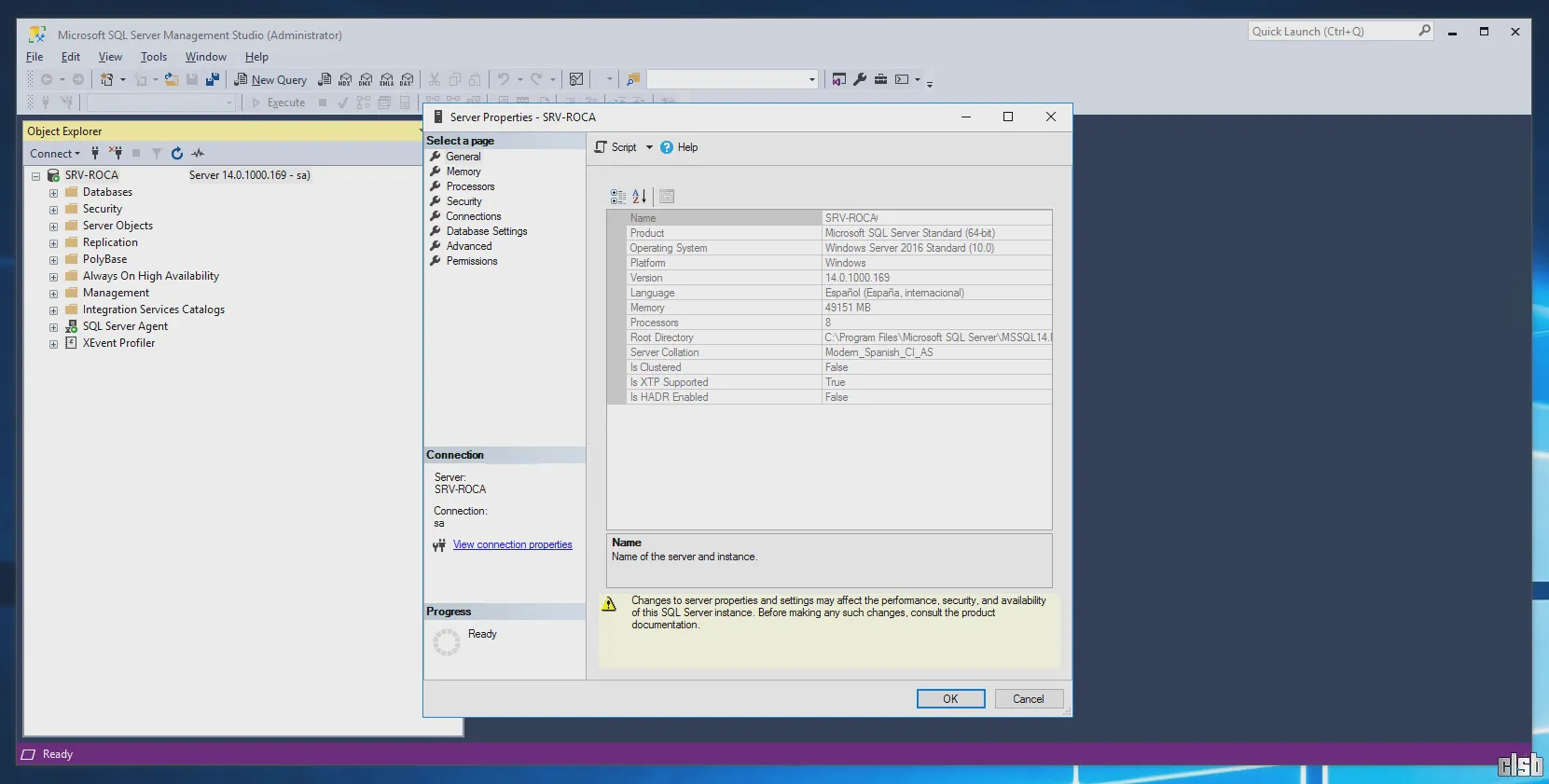
Angajații clientului, răspânziți în toate colțurile lumii, accesează aplicația ERP prin sesiuni RDP. Concret, interfața aplicației rulează direct pe server, nu pe calculatorul local al utilizatorului, ceea ce adaugă un strat suplimentar de complexitate și presiune pe resurse.
Acest material documentează deciziile tehnice și configurațiile esențiale aplicate, de la alocarea memoriei și a puterii de procesare, până la implementarea unui plan de mentenanță robust.
Pentru a proteja confidențialitatea clientului și jobul, în exemplele de cod denumirea generică a bazei de date a fost înlocuită cu „clsb”, iar în capturile de ecran, numele reale vor fi tăiate. Scopul este de a oferi un punct de plecare solid și testat în producție pentru oricine administrează o instanță de SQL Server într-un mediu ERP, nicidecum un indiciu pentru identificarea clientului.
Configurații fundamentale la nivel de instanță
Primul pas în optimizare este să stabilim regulile de bază prin care instanța SQL Server folosește resursele hardware: memoria RAM și procesorul (CPU). O configurare greșită aici este una dintre cele mai comune cauze ale problemelor de performanță. Prin urmare, vom stabili o fundație solidă pentru a ne asigura că SQL Server colaborează cu sistemul de operare, nu concurează cu acesta pentru resurse.
Alocarea strategică a memoriei: Max Server Memory
Unul dintre cei mai importanți parametri este max server memory. Acesta controlează cantitatea maximă de memorie RAM pe care SQL Server o poate aloca pentru buffer pool (cache-ul pentru pagini de date, planuri de execuție etc.). Valoarea implicită, practic „nelimitată”, este extrem de periculoasă. Fără o limită, SQL Server va consuma agresiv aproape toată memoria fizică, lăsând sistemul de operare fără resurse și forțându-l să folosească fișierul de paginare de pe disc, un proces care degradează catastrofal performanța.
Pentru un server cu 40 GB de RAM, calculul recomandat nu este un simplu procent, ci o formulă mai nuanțată pentru a rezerva memorie sistemului de operare:
- 1 GB pentru sistemul de operare.
- 1 GB pentru fiecare 4 GB de RAM instalați (până la 16 GB) » 16 / 4 = 4 GB.
- 1 GB pentru fiecare 8 GB de RAM instalați peste 16 GB » (40 – 16) / 8 = 3 GB.
Memoria totală de rezervat este de 1 + 4 + 3 = 8 GB. Astfel, valoarea optimă pentru max server memory este 40 GB – 8 GB = 32 GB, adică 32768 MB. Această modificare se poate aplica dinamic, fără a reporni serviciul SQL, folosind T-SQL.
-- Pasul 1: Verificarea valorii curente SELECT name, value, value_in_use FROM sys.configurations WHERE name = 'max server memory (MB)'; -- Pasul 2: Activarea opțiunilor avansate EXEC sp_configure 'show advanced options', 1; RECONFIGURE; -- Pasul 3: Setarea noii valori (32768 MB) EXEC sp_configure 'max server memory (MB)', 32768; RECONFIGURE;
Optimizarea utilizării CPU: Paralelismul (MAXDOP și CTFP)
SQL Server poate executa o interogare folosind mai multe nuclee CPU în paralel, un comportament controlat de doi parametri esențiali:
- Max Degree of Parallelism (MAXDOP): Numărul maxim de nuclee pe care le poate folosi o singură interogare.
- Cost Threshold for Parallelism (CTFP): Pragul de cost estimat peste care o interogare devine candidată pentru execuție paralelă.
Într-un sistem ERP, majoritatea interogărilor sunt scurte și rapide (tip OLTP). Pentru acestea, costul divizării și sincronizării sarcinii pe mai multe nuclee depășește beneficiul. Scopul este să permitem paralelismul doar pentru interogările cu adevărat complexe, cum ar fi rapoartele analitice.
- Configurarea MAXDOP: Pentru un server cu 8 nuclee logice, conform documentației oficiale Microsoft, valoarea recomandată este 8.
- Configurarea CTFP: Valoarea implicită de 5 este complet depășită pentru hardware-ul modern. O valoare atât de mică declanșează paralelism ineficient pentru interogări simple, ducând la timpi de așteptare de tip
CXPACKET. Soluția corectă nu este setarea MAXDOP la 1 (ceea ce ar anula complet paralelismul), ci creșterea CTFP. O valoare de pornire excelentă, recomandată de experți, este 50.
EXEC sp_configure 'show advanced options', 1; RECONFIGURE; -- Setarea numărului maxim de nuclee pentru o interogare EXEC sp_configure 'max degree of parallelism', 8; RECONFIGURE; -- Setarea pragului de cost pentru a declanșa paralelismul EXEC sp_configure 'cost threshold for parallelism', 50; RECONFIGURE;
Optimizarea subsistemului de stocare (I/O)
Performanța unei baze de date este în final limitată de viteza cu care citește și scrie datele pe disc. Un subsistem de stocare lent va crea un blocaj (bottleneck) care anulează beneficiile unui CPU rapid sau ale unei cantități mari de memorie RAM.
Tempdb: Fundamentul performanței tranzacționale
Baza de date tempdb este o resursă globală, critică, utilizată intensiv pentru obiecte temporare, sortări și alte operațiuni interne. O configurare sub-optimală aici va încetini întregul server.
- Numărul de fișiere: Pentru a reduce competiția internă (latch contention) pe paginile de alocare, se recomandă crearea mai multor fișiere de date. Regula generală, confirmată de Microsoft, este un fișier de date per nucleu logic, până la un maxim de 8. Așadar, pentru serverul de față, dotat cu 8 nuclee, configurația optimă este de 8 fișiere de date.
- Dimensionare și creștere (Autogrowth):
- Toate cele 8 fișiere trebuie să aibă aceeași mărime inițială pentru a distribui uniform încărcarea.
- O mărime de pornire rezonabilă este de 24 GB în total, adică 8 fișiere de câte 3 GB (3072 MB) fiecare. Pre-alocarea spațiului evită evenimentele de
autogrowth, care blochează activitatea. Autogrowthtrebuie setat la o valoare fixă în MB (ex: 512 MB), nu procentual.- Fișierul jurnal
tempdbpoate avea o dimensiune de 6 GB, cu autogrowth tot de 512 MB.
- Plasarea fizică: Fișierele
tempdbtrebuie plasate pe cel mai rapid disc disponibil (ideal SSD NVMe), separat fizic de fișierele bazei de date principale.
Gestionarea fișierelor de date (.mdf) și a jurnalului (.ldf)
O regulă fundamentală este separarea fizică (pe discuri/LUN-uri diferite) a fișierelor de date de cele de jurnal tranzacțional. Acest lucru se datorează tiparelor de acces fundamental diferite:
- Fișierele de date (.mdf): Acces predominant aleatoriu (random I/O).
- Fișierul jurnal (.ldf): Acces strict secvențial (sequential I/O).
Amestecarea lor pe același disc fizic duce la o mișcare haotică a capetelor de citire/scriere și degradează sever performanța. De asemenea, este vitală pre-alocarea spațiului pentru a evita pauzele de performanță cauzate de autogrowth.
Opțiunea de bază de date AUTO_SHRINK nu trebuie activată niciodată pe un server de producție. Operațiunile de micșorare a fișierelor (SHRINKFILE) trebuie evitate, deoarece cauzează o fragmentare masivă a indexurilor și consumă inutil resurse.
Implementarea unui plan de mentenanță robust
O bază de date necesită mentenanță regulată pentru a preveni degradarea performanței. Operațiunile zilnice duc la fragmentarea indexurilor și la invalidarea statisticilor pe care se bazează motorul SQL pentru a alege planuri de execuție eficiente.
Mentenanța inteligentă a indexurilor și statisticilor
În loc să reconstruim orbește toți indexurii, abordarea corectă este una condiționată de nivelul de fragmentare:
- Fragmentare < 10%: Nu este necesară nicio acțiune.
- Fragmentare între 10% și 30%: Se recomandă
ALTER INDEX REORGANIZE, o operațiune online cu impact redus. - Fragmentare > 30%: Se recomandă
ALTER INDEX REBUILD. În ediția Standard, aceasta este o operațiune offline care blochează tabelul, deci trebuie planificată în ferestre de mentenanță.
Pentru a automatiza acest proces inteligent, este ferm recomandată implementarea scripturilor de mentenanță gratuite și recunoscute în industrie ale lui Ola Hallengren. Acestea aplică automat logica de mai sus, actualizează statisticile doar când este necesar și oferă o soluție mult mai flexibilă și eficientă decât planurile de mentenanță standard din SSMS.
Asigurarea integrității și recuperabilității
- Verificări de integritate: O sarcină săptămânală care execută
DBCC CHECKDBeste non-negociabilă pentru a detecta timpuriu corupția datelor. - Strategia de backup: Pentru o bază de date ERP în modelul de recuperare FULL, sunt necesare:
- Backup complet (Full): Zilnic, ca bază pentru restaurare.
- Backup de jurnal tranzacțional (Log): Frecvent (ex: la fiecare 15-30 de minute) pentru a permite recuperarea la un moment specific în timp (point-in-time recovery) și pentru a preveni creșterea necontrolată a fișierului .ldf.
Monitorizare proactivă cu Query Store
Optimizarea este un proces continuu. Versiunile moderne de SQL Server (începând cu 2016) includ un instrument puternic numit Query Store, care funcționează ca o „cutie neagră” pentru performanța interogărilor, capturând un istoric al acestora, planurile de execuție și statisticile de performanță. Opțiunea de a captura statistici de așteptare (WAIT_STATS_CAPTURE_MODE) este disponibilă începând cu SQL Server 2017, fiind un element important în diagnoza avansată.
Activarea se face simplu prin T-SQL, iar odată activat, oferă rapoarte esențiale:
- Top Resource Consuming Queries: Identifică rapid interogările care consumă cele mai multe resurse.
- Regressed Queries: Detectează interogările a căror performanță s-a degradat, permițând forțarea unui plan de execuție anterior, mai bun, cu doar câteva clicuri.
ALTER DATABASE [clsb] SET QUERY_STORE = ON (
OPERATION_MODE = READ_WRITE,
CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 30),
DATA_FLUSH_INTERVAL_SECONDS = 900,
MAX_STORAGE_SIZE_MB = 1024,
INTERVAL_LENGTH_MINUTES = 60,
QUERY_CAPTURE_MODE = AUTO,
WAIT_STATS_CAPTURE_MODE = ON
);
Sinteză și listă de verificare
Pentru a consolida recomandările, iată o listă de verificare a acțiunilor cheie:
- Configurare Instanță:
- [ ]
Max Server Memorysetat la 32768 MB. - [ ]
MAXDOPsetat la 8. - [ ]
CTFPsetat la 50.
- [ ]
- Configurare Stocare:
- [ ]
tempdbconfigurat cu 8 fișiere de date de dimensiuni egale. - [ ] Fișierele
tempdbsunt pe cel mai rapid disc, separat de baza de date principală. - [ ] Fișierele
.mdfși.ldfale bazei de date ERP sunt pe unități fizice separate. - [ ]
Autogrowtheste setat la o valoare fixă în MB. - [ ] Opțiunea
AUTO_SHRINKeste dezactivată.
- [ ]
- Mentenanță:
- [ ] Un job inteligent de mentenanță (ex: Ola Hallengren) rulează săptămânal.
- [ ]
DBCC CHECKDBrulează săptămânal. - [ ] Backup-uri complete zilnice și de jurnal la fiecare 15-30 minute.
- Monitorizare:
- [ ]
Query Storeeste activat și monitorizat periodic pe baza de date ERP.
- [ ]
Concluzie
Configurațiile prezentate în acest ghid pun bazele unui server SQL performant și stabil, însă optimizarea este un proces continuu. Pentru a trece de la intervenții manuale la o soluție complet automatizată, am documentat pe larg cum se poate implementa un program complet de mentenanță a bazelor de date SQL.
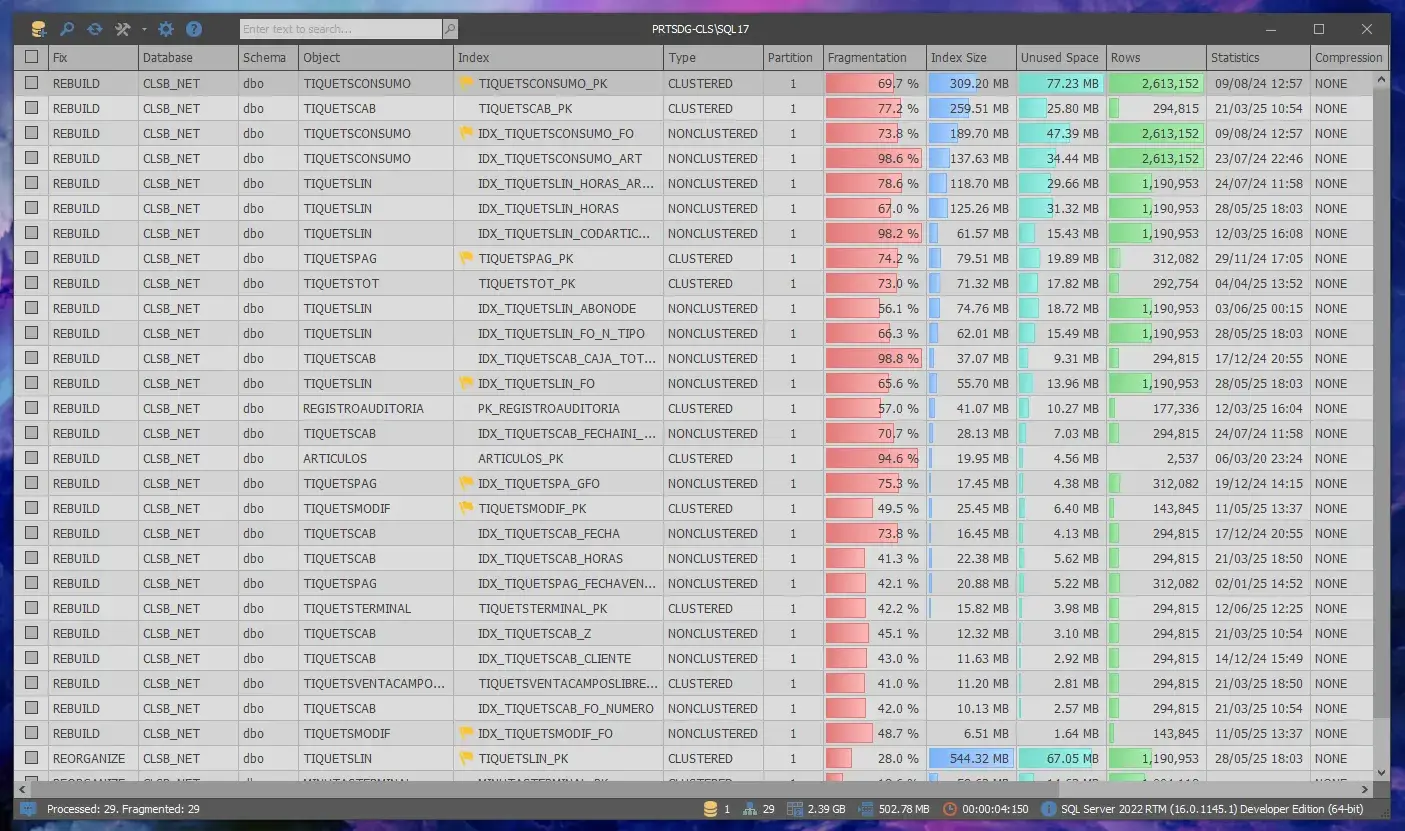
Acesta preia sarcinile repetitive de verificare, backup și reorganizare a indexurilor, asigurând sănătatea sistemului pe termen lung, fără a mai fi necesară ajustarea setărilor direct din interfața aplicației.